Segmentation Workshop
Introduction
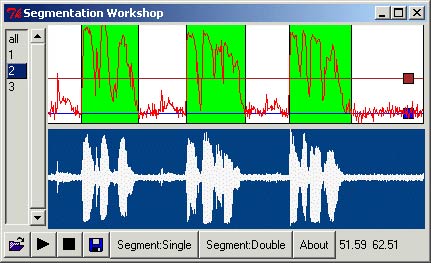
A classic problem in automated speech recognition is to isolate individual words and syllables. The process of identifying the beginning and ends is called segmentation. In the above example we are applying it to "123.wav" file, which consists of 1, 2, 3 spoken in English, German, and Chinese. Two passes are made. The first pass (above) seperates out the spoken portion from the background noise. In this case, I have a rather noisey linux box which is my server. It produces the blocks of "123" in each language, seperating the phrazes spoken in each language, which may be played and saved using the control on the left. The second pass (below) seperates the individual words (ie syllables), again which may be played and saved using the control on the left.
The Algorithm
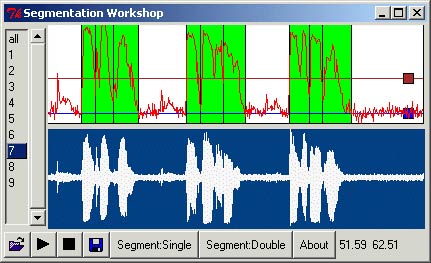
This application explores the segmenting of a sound stream into components. This is done in two passes, calledsingleSeg
Time intervals are created by considering those periods where the sound is above a given min threshold. The horizontal blue line (with a box attached) determines that min threshold. However, since we are dealing with voice, intervals which are too short in duration are discarded. Likewise, we assume the speaker is not whispering, so portion of the sound made by the speaker should be reasonably loud, thus intervals which do not contain a point of a minimum power peak are discarded. Intervals left over are retaineddoubleSeg
Further refines the components determined by singleSeg It first applies single seg, using the blue horizontal line setting, then reapplies single seg to these results using the red horizontal line setting. It then constructs the final segmentation.Features:
- open
- play
- stop
- save
- about
- single pass: isolates sound from background noise
- double pass: attempts to break continuous speech into segments